
A Microsoft researcher (Adrian de Wynter) recently dropped an amazing paper title “If LLMs Have Human-Like Attributes, Then So Does Age of Empires II”. In the paper he built a small working neural network inside Age of Empires II using goats, bridges, grass, ice ramps, and the game’s map editor.
That sounds ridiculous, and it is supposed to.
The point is not that goats are intelligent. The point is that we need to be very careful when we look at a system’s behaviour and then attach human words to it. If an AI system produces a human-like answer, we have not automatically observed understanding, empathy, belief, intention, or reasoning. We have observed an output.
That distinction matters in science, and it also matters in IT. Good science and good IT both require the same discipline: separate what was observed from what was inferred.
Summary
The paper If LLMs Have Human-Like Attributes, Then So Does Age of Empires II challenges the way people talk about large language models.
Many discussions about AI move too quickly from behaviour to human-like claims. A model gives a thoughtful answer, so we say it understands. It gives a caring answer, so we say it has empathy. It explains something clearly, so we say it is reasoning like a person.
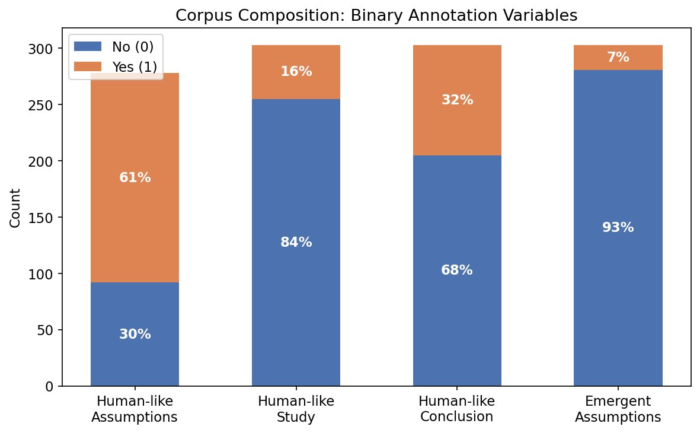
Adrian reviewed 315 AI papers from mid-2024 to mid-2026, drawing from Semantic Scholar and arXiv, and using GPT-5.2 to help filter the results. What stood out was not just the conclusions, but the starting assumptions. In 57% of the papers, the premise already treated LLMs as having human-like traits. In 36%, the conclusions aligned with that framing. And in the smaller group of 47 papers where those traits were the main research question, 77% concluded in favour of anthropomorphic attributes.
The problem is that those things were not directly observed, what we observed was text.
The text may be useful. It may be accurate. It may be emotionally convincing. It may even be better than what many people would produce in the same situation. But the output alone does not prove the inner state behind it.
That is why the Age of Empires II example is so effective.
The researcher built a tiny neural network inside the game using ordinary game objects. Goats acted as data bits. A goat standing on grass represented one state, and a goat standing on a bridge represented another. The game’s scenario editor was used to build logic gates, while ice ramps and waiting goats helped keep the timing of the calculation under control.

The result was a simple network that could learn a basic logical function. Nobody looks at that and says, “The goats understand logic.” And that is exactly the point.
When the substrate looks silly, we are less tempted to humanise it. When the interface is a chat window, we are much more tempted to do so.
The danger is that the interface changes our interpretation, even when the evidence has not changed enough to justify the conclusion.
The assertion is not the machine learning and large language models are not useful (“AI”), but rather that they are not human or have human traits.
Breakdown of the article
The article describes a deliberately strange experiment by Adrian de Wynter, a researcher at Microsoft and the University of York. He used the Age of Empires II map editor to construct a working neural network out of in-game objects.
At a technical level, the setup is absurd but meaningful. Goats are used as signal carriers. Grass and bridges represent different binary states. The scenario editor provides the rules that make the system behave like logic gates. The network itself is tiny, but it is enough to make the point: computation can be represented in unusual places.
This is not presented as a serious proposal for building practical AI inside a medieval strategy game. It is a critique of how easily AI research and AI commentary can slide into human language when describing systems that generate language.
The paper’s argument is not simply “AI is dumb” or “LLMs are useless.” That would be too easy, and also wrong.
The better argument is that we should be more careful with our claims.
If we say a model has empathy, what exactly did we measure?
If we say it understands, what would count as evidence?
If we say it has anxiety, morality, intention, or self-awareness, are we measuring those things directly, or are we interpreting behaviour through a human lens?
The Age of Empires II example forces the question because it removes the emotional pull of the chat interface. When a chatbot says, “I understand how you feel,” the words feel familiar. They invite us to respond socially. But when a goat moves from grass to a bridge in a game editor, we do not feel the same pull.
Yet both are still systems producing behaviour through rules and computation.
That does not mean the systems are identical in scale, usefulness, or complexity. Modern LLMs are vastly more powerful than a toy neural network in a game editor. But the philosophical and scientific warning still stands: do not confuse the representation with the property.
The way something appears to us is not the same as what has been measured.
Why this matters for IT
This is where the article connects strongly with IT and cybersecurity. In IT, we get into trouble when we confuse a conclusion with an observation. A user may say, “The system deleted my file or I got hacked.”
That may be true, but it is not yet the evidence. It is a claim that needs investigation. The evidence may be an audit log, a OneDrive sync event, a retention policy, a permission change, a device issue, or a user action.
The same applies in security.
“The account was hacked” is not the starting observation. The starting observations are things like unfamiliar sign-ins, MFA prompts, token activity, mailbox rules, OAuth consent grants, password resets, endpoint alerts, or changes in behaviour.
Only once we examine those signals can we build a responsible conclusion. AI should be handled with the same discipline. When a model gives a useful answer, we can say the answer was useful. When it solves a problem, we can say the output matched the task.
But we should be slower to say that the model understands, believes, wants, feels, or intends something.
Those words may be convenient in everyday conversation, but they become risky when we treat them as measured facts.
The practical business lesson
This does not make AI less valuable. In fact, it makes AI more useful, because it moves the conversation away from hype and toward governance. For business, the best question is not, “Does the AI understand our company?” A better set of questions would be:
Can it retrieve the correct policy?
Can it summarise the right document?
Can it respect permissions?
Can it cite its sources?
Can it produce a useful first draft?
Can it identify when it does not know?
Can it fail safely?
Can it be audited?
Those are observable things. They can be tested. They can be controlled. They can be improved.
That is where AI becomes useful in real organisations.
Not because we pretend the system is human, but because we define what good performance looks like and measure it.
Final thought
The lesson I take from the paper and the article is simple: In science and IT, stick to what can be observed.
Then be clear when you move from observation to interpretation.
As AI systems become more conversational and more embedded in business processes, this discipline will become more important, not less. The more human the interface feels, the more careful we need to be about the claims we make.
Trust should not come from fluency, trust should come from evidence. (Oh how I wish that was always true).
In IT terms, a system earns trust when it is observable, testable, auditable, and controlled. That is a good standard for AI too.