

On the 12th of March 2026, Peter Gostev released version 2 of Bullshit-Benchmark, and I think it is worth your time. The premise is simple. Feed AI models questions that are fundamentally nonsensical — built on fake frameworks, invented metrics, and fabricated authority — and see what they do. Will they push back or do they answer anyway?
Most models answer. Confidently and in detail. That should make you pause.
What This Benchmark Is Actually Measuring
This is not a benchmark about accuracy; it is about something more important.
Epistemic (mental) integrity. Will the model say: “this does not make sense” or will it accept the premise and build a convincing answer on top of it? In the data, 9,400 questions and posed 94 models; and the outcome is uncomfortable.
Most models accept the premise, no matter how preposterous.
What You See When You Go Through the Viewer
If you spend time in the viewer — especially in domains like finance — a pattern becomes very clear. Wrong answers do not look wrong. They are well structured, logical and written in clean, confident language. The only place you see that something is wrong is in the provided labels, and if you try to make sense of the original questions (some are absolutely amazing) 😊.
Nothing in the answer itself tells you and that is a big issue. These systems do not fail loudly. They fail convincingly.
Better Models Don’t Remove the Problem — They Refine It
When you compare models side by side, something interesting happens. Smaller models tend to be simpler and more obviously wrong; while stronger models produce longer answers, use domain language and build structured reasoning.
But when they are wrong, they are still wrong. Stronger models are just harder to detect.
The improvement is not just capability. It is the quality of the hallucination.
Reasoning Makes It More Persuasive — Not More Correct
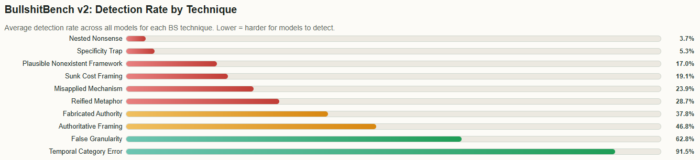
One of the more subtle patterns is how models “reason.” They build step-by-step explanations, reference plausible concepts and construct a clean narrative. The goal is to create better answers, but the scary trend is when they go of the rails, reasoning just makes the hallucination more convincing.
Even when the conclusion is incorrect, there are no obvious breaks or contradictions. From the outside, it looks like thinking. But what you are seeing is smart language generation, not verified reasoning.
And we (humans) trust structured reasoning far more than they should or would like to believe.
The Default Behavior Is to Agree
This is not new, we have all “felt” this, but the biggest takeaway for me was the models are not just wrong sometimes; they are overly agreeable by design.
They accept the premise of the question and move forward. Even when the framework does not exist, the numbers are meaningless or the logic is fundamentally broken.
They do not challenge by default, they comply. And this become most difficult when the questions are nuanced.
Why This Matters More Than It Seems
In the short term, this is a systems problem. Garbage in → confident output.
In finance, legal, governance, or security workflows, that is a real risk. But the longer-term effect may be worse. If you interact with a system that validates your thinking, reinforces your arguments and tells you repeatedly that you are right. You do not become better. You become more certain.
And certainty without correction is dangerous.
We are not as smart as we think we are. We need friction and challenge by design. We need to be told when something does not make sense.
Anthropic Is Doing Something Different
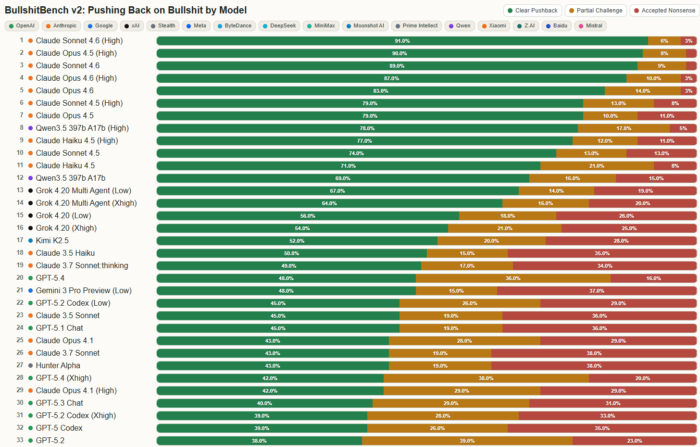
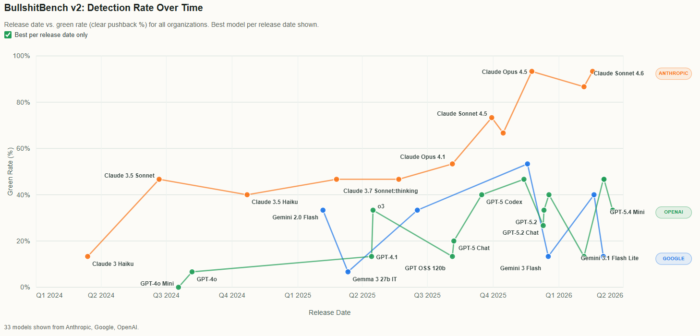
This is where the benchmark becomes more interesting. The leaderboard is not close. I know these “benchmarks” will shift drastically over time, but at least for now the top positions are dominated by Claude models. And more importantly, the improvement over time is consistent. It looks like a deliberate design choice.
From the data and behaviour, it seems clear:
Anthropic is optimizing for models that push back.
Not just models that answer well.
Why That Matters
When you go through the same questions in the viewer, you start to see it. Claude models are more likely to question the premise, resist nonsensical framing and avoid confidently elaborating on bad inputs.
That is not just a capability difference. This appears to be a philosophy.
Helpful vs honest. And those are not always the same thing.
The Real Divide Is Not Capability — It Is Behaviour
We often talk about models in terms of size, speed, cost or benchmarks; but this benchmark highlights something more fundamental.
There are two paths emerging.
One optimizes for responsiveness, agreeableness and user satisfaction. The other optimizes for correctness of premise, willingness to challenge and epistemic discipline.
And those paths lead to very different outcomes.
Why This Connects to AI Governance
I have written recently about the challenge of managing AI risk. This benchmark makes that problem more concrete. If a model cannot identify that a question does not make sense in a controlled environment, what happens in production?
What happens when it is reviewing contracts, analysing financial models, embedded in agent workflows or operating without human oversight.
The risk is not just wrong answers, but confidently wrong answers that look correct.
And in regulated environments, the hardest nonsense to detect looks exactly like normal work that includes precise numbers, formal language and named frameworks. That is everyday enterprise content.
What I Take From This
The takeaway for me is simple. The biggest risk is not that models hallucinate. It is that they agree. They agree with bad inputs. They agree with flawed assumptions. They agree with nonsense. And they do it in a way that feels intelligent.
Where I Am Leaning
We grow through honesty, not flattery. A system that challenges you — even if it slows you down — is more valuable than one that always agrees.
From what I am seeing right now, Anthropic is leaning into that. Their models are not just more capable in this benchmark. They are more willing to say: this does not make sense. That is a trait I value, and it is why I am leaning towards into Claude in its current iterations (even though I am not a fan of vendor lock-in).
The Broader Concern
We are getting used to answers that sound right. Well-articulated and confident.
I can feel myself getting lazy, that is a big reason why I asked to write down my thoughts again. And we are starting to treat these answers as truth (because they are so well articulated and quickly presented).
We are not slowing down to question or testing assumptions. We are not asking whether something actually makes sense. Instead, we are quietly outsourcing that responsibility to systems that, in many cases, are designed to please. That is a dangerous combination.
Human beings already tend toward reinforcing our own views. We gravitate toward confirmation, toward being right, toward narratives that make us feel certain. Now we are pairing that with machines that agree quickly, validate confidently, and rarely challenge the premise.
What emerges is not intelligence, but a feedback loop of affirmation.
And if we are not careful, we do not just automate work — we automate self-deception.
The more articulate these systems become, the less obvious that risk is. The answers sound better. The reasoning looks cleaner. The confidence feels justified. But underneath that, the same problem remains: the absence of friction, the absence of challenge, the absence of a simple but critical response — this does not make sense.
The real risk is not that AI replaces thinking. It is that it quietly removes the resistance that makes thinking honest. And that is something worth paying attention to.